
Achieving Consensus with Raft
A gentle introduction to the Raft consensus algorithm.

This time we're going to take a look at the Raft consensus algorithm. The algorithm aims to provide a simple implementation for consensus.
Ok, so why do we even need consensus algorithms?
If you are hosting all your data on a single instance of a database, then you are going to have a big problem. The classic single point of failure issue. That one little box goes down? Your entire application is down, costing you money.
Ok, have replicas, simple right?
Let's say you have two replicas of a database spread between two nodes. Consider the following operations:
write(x, "hello") -> x = "hello" in node 1
write(x, "world") -> x = "world" in node 2
read(x) -> ???The first operation was performed in let's say node 1. The second operation on the second replica. How do you know what the correct value of x is when you read? How do you ensure the writes propagate to all other instances? The replicas need to agree on a value and send it to a client. In other words, there needs to be a consensus between the nodes on what the correct value is.
Consensus algorithms do this. In a replicated state machine, or replicated database, you need consensus to agree on what values to show the client and maintain a coherent view of the database.
Raft is one of the many consensus algorithms out there. Paxos and ZooKeeper are some of the other major ones. Paxos was the defacto consensus algorithm for many years until the authors of Raft thought this could be a lot easier. They spent time finding an algorithm that's not only correct but also easy to understand, the paper they published is called "In Search of an Understandable Consensus Algorithm".
Alright. With that background let's look at Raft.
Let's start with a definition of what a server or node looks like in Raft. A server has three components:
- Log: This is a log containing a history of operations and pending operations to perform on the state machine.
- State Machine: This can be thought of as your database.
- Current Term: Each server internally keeps track of the current term, a monotonically increasing number. This is mainly to detect stale states. (See below for term explanation)
A server can be in three states:
- Follower: This is the most simple state because followers don't do much. They listen to requests from the leader or call for an election when the current leader dies.
- Candidate: A follower goes into candidate status when it does not receive a message from the leader within a certain period.
- Leader: The leader handles all requests from the client. It later replicates the request operations on other followers. A leader stays as a leader until it crashes.
Just like presidents are elected for a term, leaders in Raft are elected for a term. Though how long a term lasts depends on the health of the leader. Whenever a new leader is elected the term value is incremented by 1. Below is an example of multiple terms in a cluster:
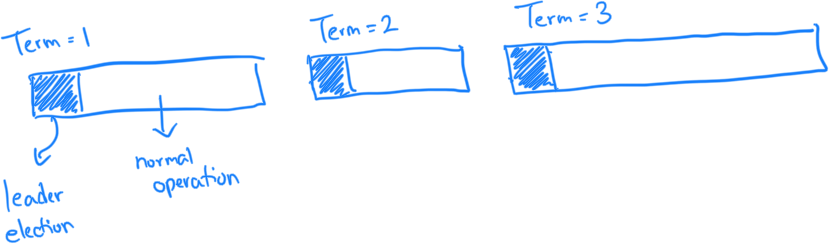
The Raft paper breaks the problem of consensus into 3 distinct subproblems:
- Leader Election
- Log Replication
- Safety
Leader Election
Leader election is the problem of deciding who in your cluster should be the leader for the current term. Raft guarantees there is at most one leader for a term. This is to mitigate split-brain issues where there are two leaders each with its view of the data.
Each term starts with the leader election. A follower at random declares itself as a candidate and starts collecting votes from other servers. Once it receives a majority vote, it will declare itself as a leader and let everyone else know.
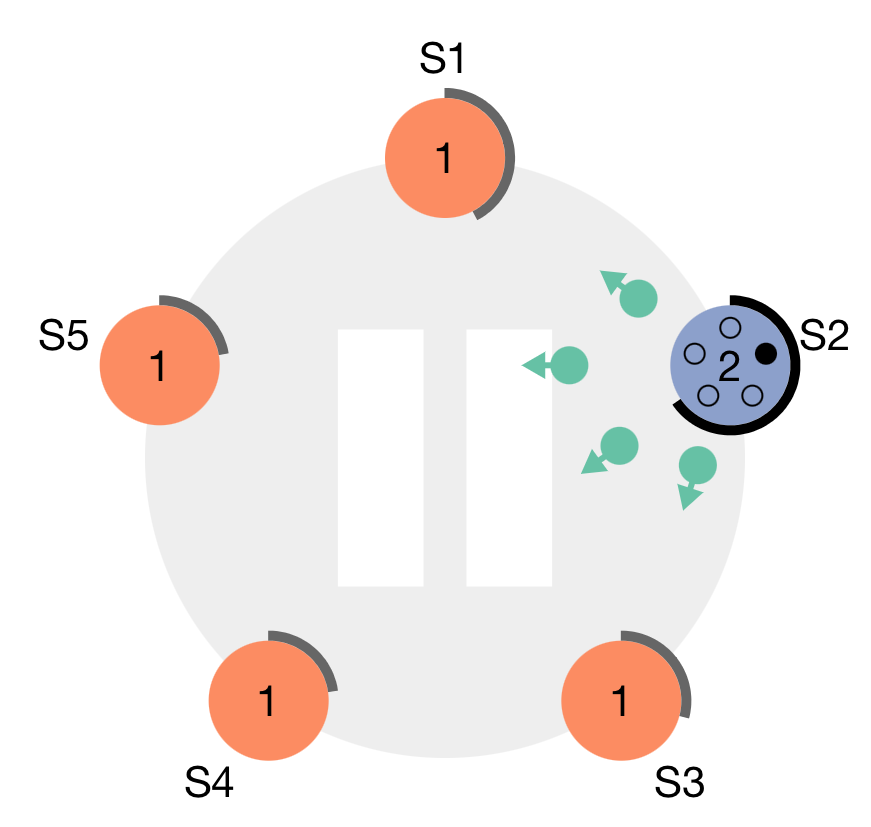
What happens if two followers become candidates at the same time?
Followers can only cast one vote per term, so votes are cast on a first come first serve basis. If a majority vote is achieved for one candidate, the second candidate converts to a follower once it learns that a leader has been elected.
If a majority vote has not been achieved, the election process is cast again. The intervals to become a candidate are randomized to ensure there is a low chance of another failed election.
Log Replication
The second subproblem in Raft is replicating the data between servers. This is done by replicating the log first and applying the operations in the log to the state machine.
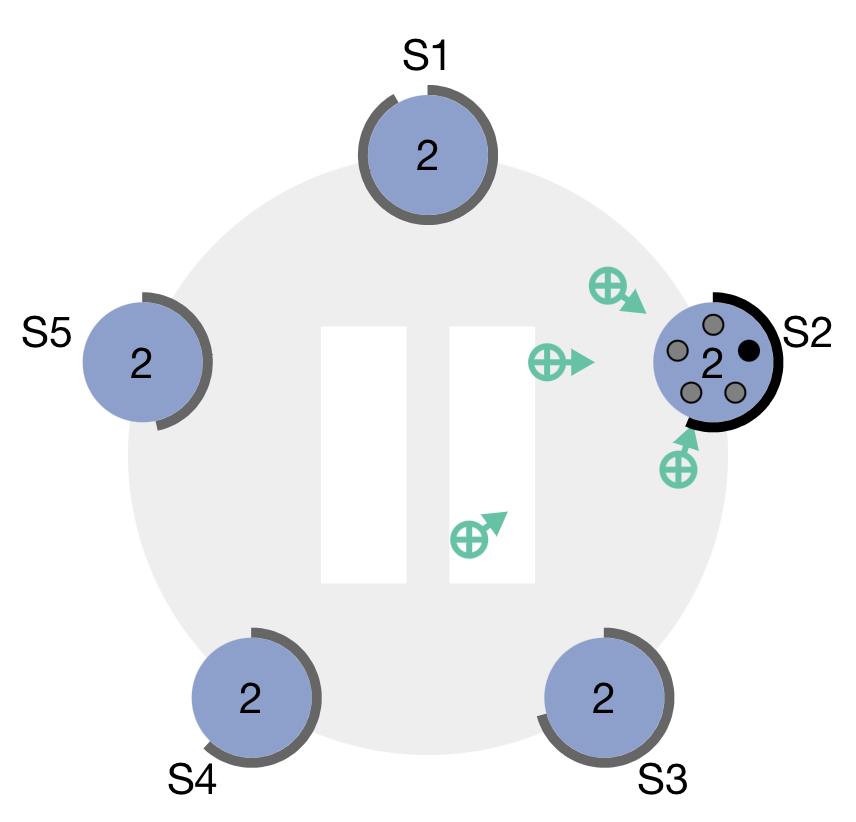
Once the leader is determined, we can start serving requests. All requests come to the leader, and the leader makes a note of the operation to perform in its log. Then it will tell all the other followers about this new entry and wait for their response. Once the leader learns that majority of the followers have written the operation in their log, it will commit the value. The operation is applied to the state machine afterward.
It's important to note that operations are applied only after the value has been committed. Why? At that point, it is safe to do so. If the leader crashes while performing the operation, the result is not lost because it has been replicated by a majority of the followers. The newly elected leader will have this operation in its log and apply it at some point.
Safety
The final subproblem is safety. Safety is the property that ensures your data is consistent across replicas. The only way that can be done is if all the replica logs contain the same operations in the same order.
To ensure safety, there is an extra condition for a candidate to move into a leader role. The condition is that a candidate must contain all the committed operations so far in its log. This is verified when requesting a majority vote. Since committed values are by definition present in the majority of the cluster, a follower should have the list of all committed values, or the candidate is the only server with all the committed values.
The second restriction Raft places to ensure safety is to not let leaders commit values from previous terms by counting replicas. Log entries are only committed if it is from the current term, everything before that entry is also committed.
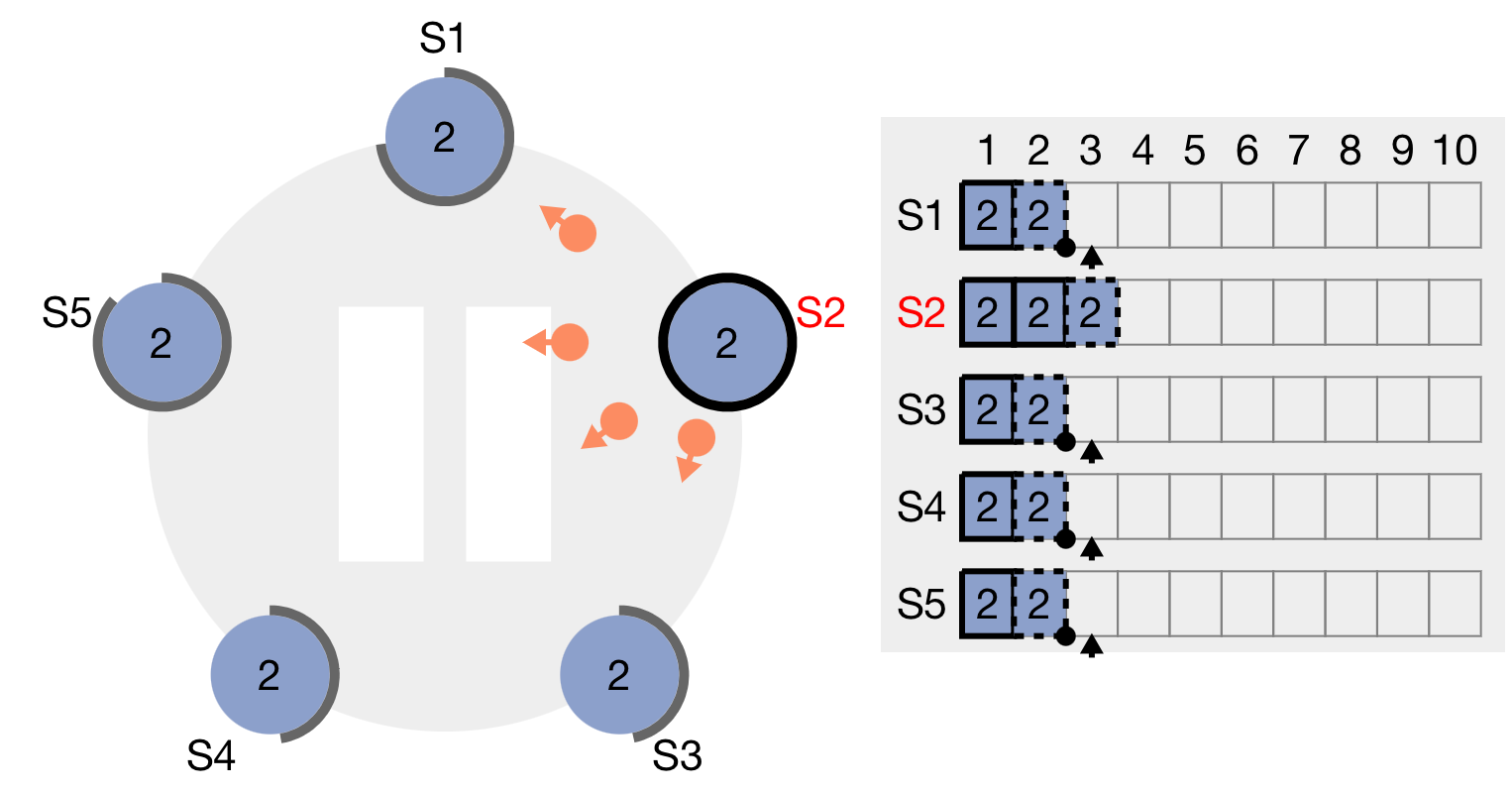
The following is bringing everything together with an example of a leader crashing after a request:
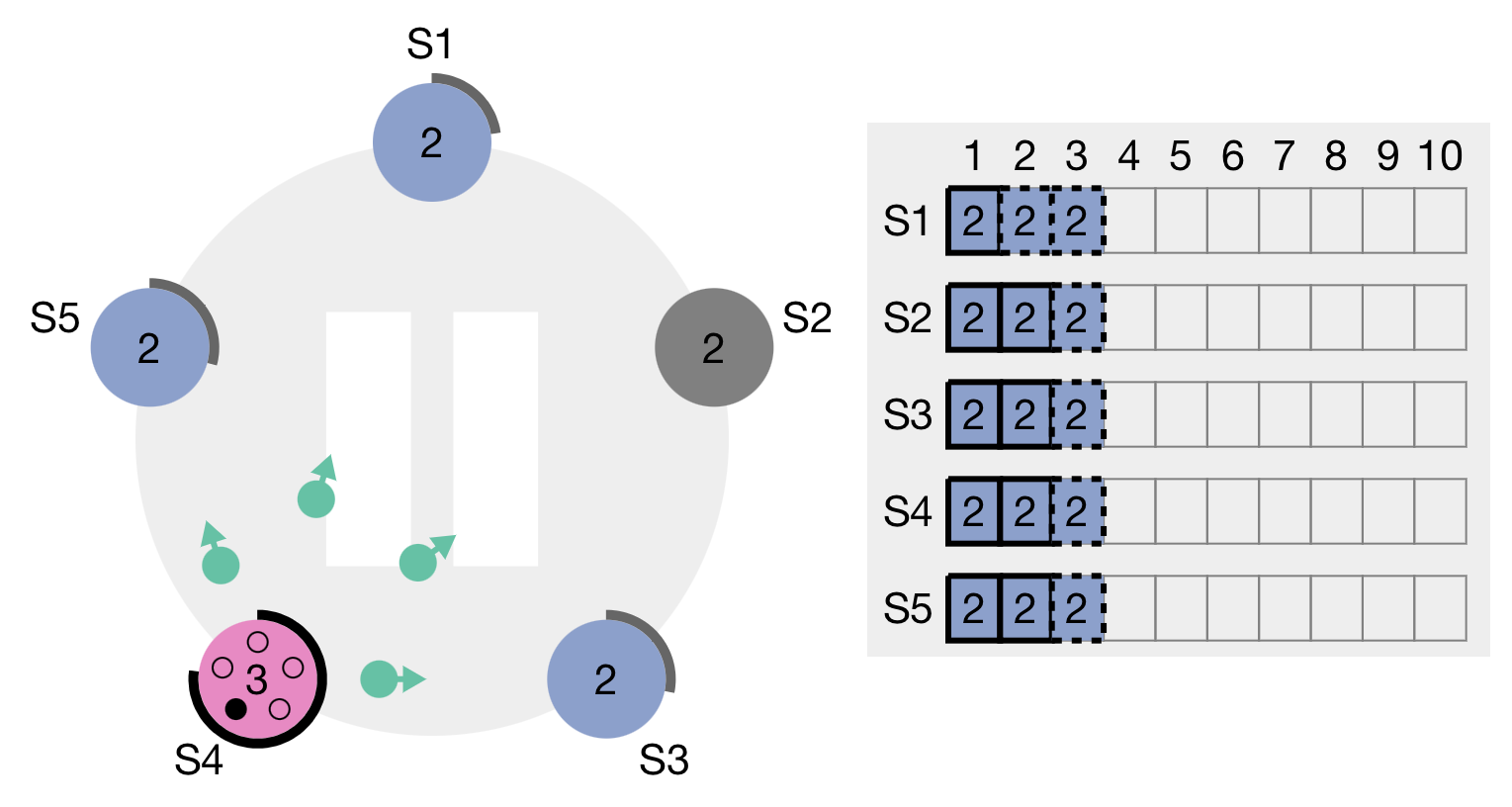
Here leader S2 receives a request, makes a note of the operation in the log, and is now sending this to the followers. In the figure below, S2 has three values, all denoted with 2. The 2 here is the current term number, the operation itself is not relevant for understanding this so it is omitted.
Now, leader S2 fails, and a new election process begins, the new term is 3:
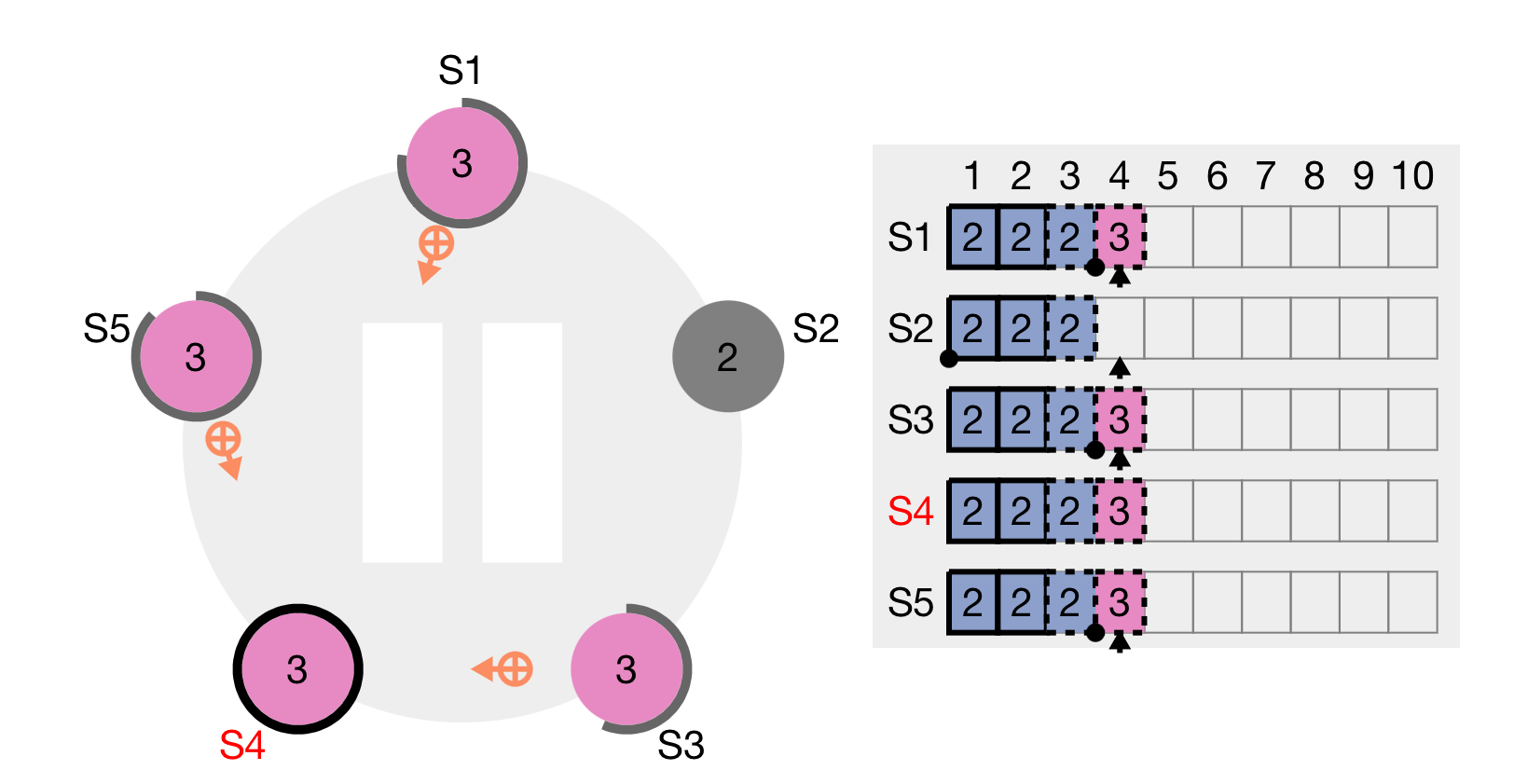
S4 is elected the new leader. It replicates the value from the previous leader, but, it does not commit the value (solid line across operation) because it is from an older term. This is to ensure data safety as discussed. After a few more seconds, S4 gets a new request for its term, and replicates the value across the remaining followers:
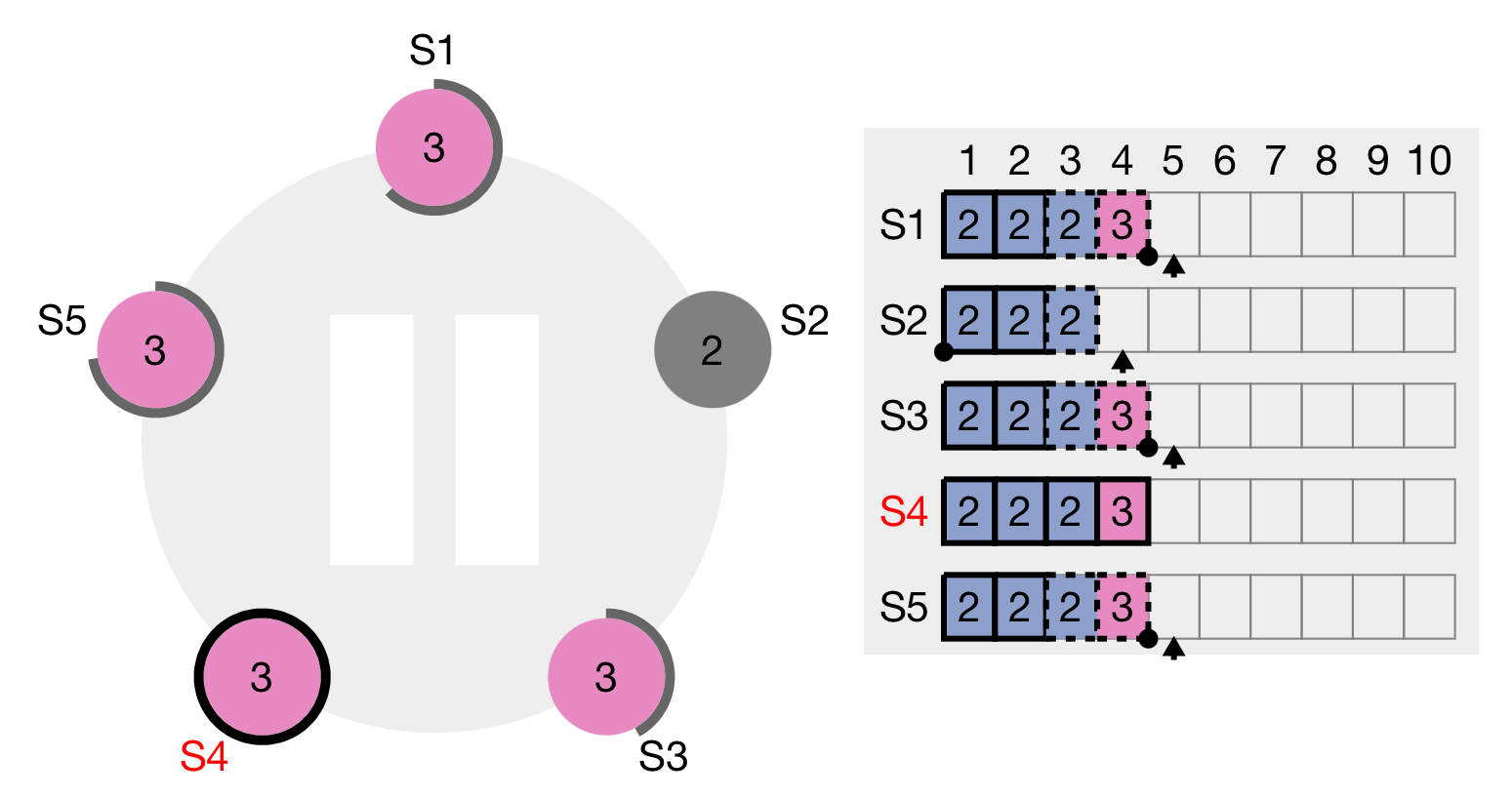
Once it has been replicated across a majority of nodes, S4 commits not only the new value but also the previous term's value because it is safe to do so.
The implementation for Raft is simple compared to Paxos, and I don't cover much of those details here for brevity. If you've used Kubernetes, you've used Raft indirectly as etcd, the storage engine for k8s uses Raft consensus. Many other database systems such as CockroachDB, TiKV, and MongoDB use Raft under the hood.
This was a longer article than usual, and thanks for making it to the end. If you have enjoyed reading this, please consider subscribing (it's free) and sharing it with a friend.
I could not have written this without the following resources:
- The Raft Paper by Diego Ongaro and John Ousterhout
- Database Internals by Alex Petrov
- A video explanation of Raft by John Ousterhout
- This visualization tool that provided the screenshots in the post