
Consistency Models

Availability is critical for your applications in today's world. If Amazon goes down? Millions of people can't place orders to buy things they want or watch the new Lord of The Rings show on Prime Video.
Uber or Lyft goes down? Can't get to your favorite restaurant on a Friday night.
Google goes down? Let's hope that doesn't happen.
You need availability and since most applications are stateful, i.e, they store and operate on data, your data needs to be highly available. Meaning you need to replicate your data.
Availability isn't the only reason for replication. Latency is your second enemy. Let's say you're Netflix, you don't want users in India reaching out to a server in the US to handle requests. Your users would leave you for Amazon Prime or Disney+ because they don't buffer every few seconds. Solution? Replicate your data as close to your users as possible.
Another reason for replication? Scalability. Your one database node might be fine with handling 5 requests per second. Suddenly your app kicks off and has 5000 requests per second. There are probably a lot of alerts on your Slack channel now.
Now that a strong case for replication has been established, you go ahead and replicate your data across some nodes. Great.
After replication, you notice that your data is not consistent. Nodes don't have the same copy of the data leading to inconsistent behavior.
Consider this case with data replication without consistency:
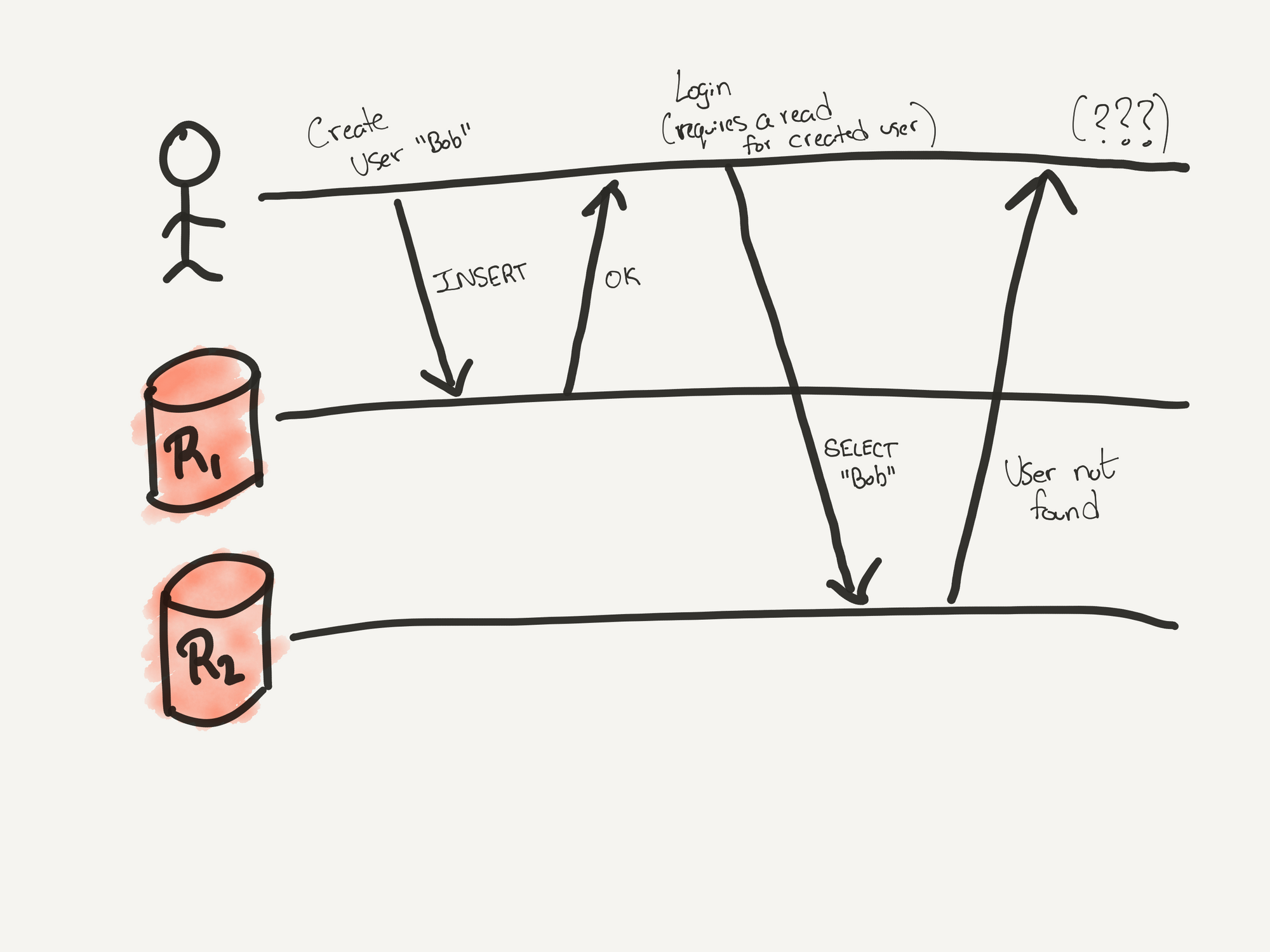
Here is the typical case of a user signing up for your application. The request goes through and the user's details are inserted into replica 1 (R1). Then the user navigates to the login page, enters their credentials, and hits login. This time your application reaches out to replica 2 (R2) to see if the credentials are valid. The user doesn't exist in R2. You end up with a very confused user when they get a user not found message.
To ensure this doesn't happen, we need consistency models in our databases.
Consistency models are guarantees provided by a replicated database when accessing data. I'm going to go through three consistency models in this article:
- Ideal Model
- Eventual Consistency
- Strong Consistency or Linearizability
Ideal Model
The ideal model is as soon as you write a value to one replica, it is instantly available for reading on all other replicas. There's no way to achieve this in real life because of the fallacies of distributed systems.
Eventual Consistency
This is the consistency model provided by most databases. Under this model, the value you have written will eventually propagate to all the other nodes. There's no upper bound for the time it could take. Could be 5 seconds from now or 5 hours from now.
Here's an example of eventual consistency:
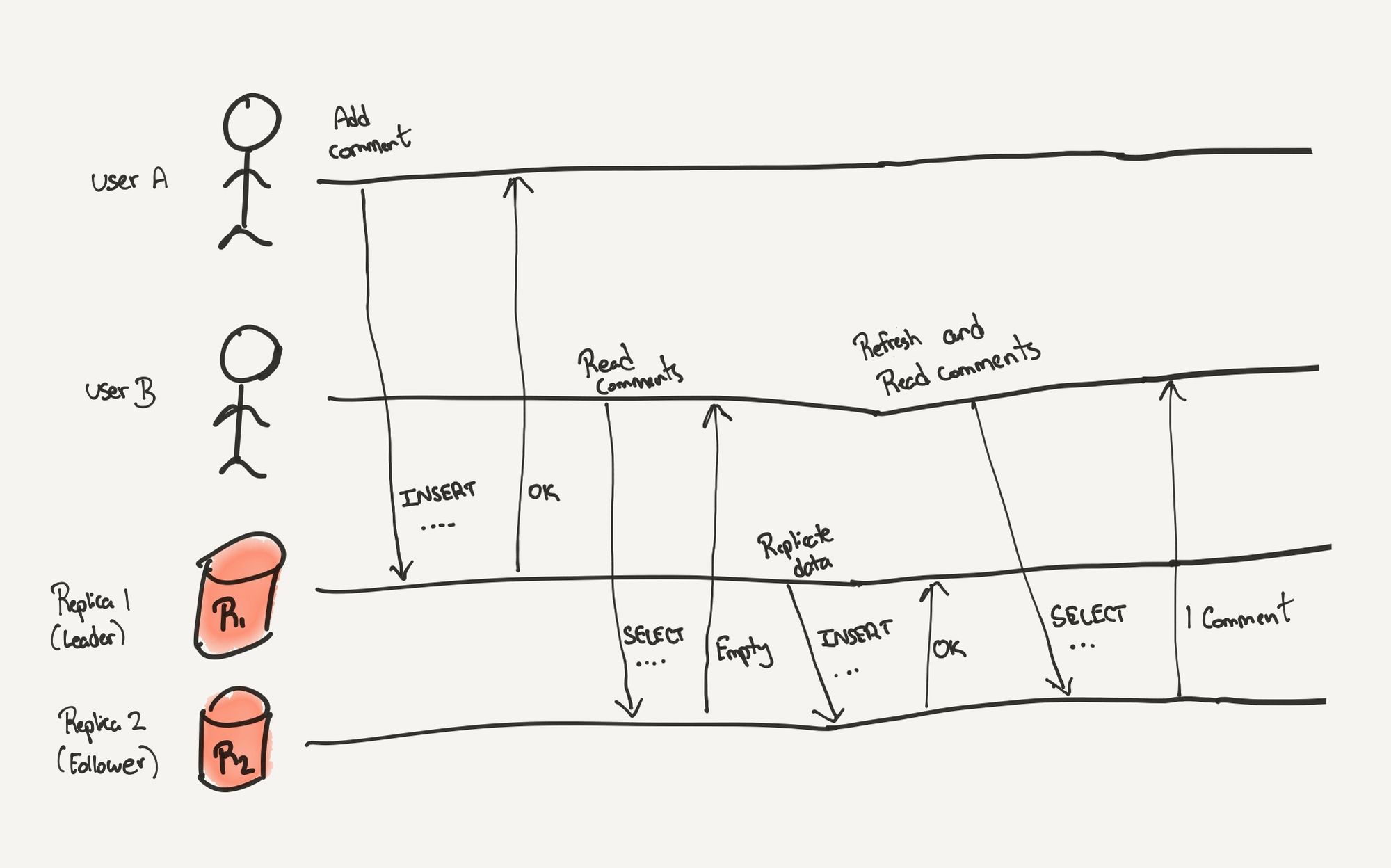
User A adds a comment on a Twitter post. This was inserted into replica 1. Replica 1 is also the leader of the cluster meaning it will eventually replicate data to other followers.
User B shortly requests to look at the comments for the same post. The request is served by the second replica which does not have the new data yet. The response is empty.
Then, the cluster leader decides to replicate the new data to its followers.
User B refreshes the post, and this time the second replica has the new comment and sends it back to the user.
User B doesn't see the new data immediately but eventually sees it.
In most cases, this model works. Mostly for cases where reading stale data isn't a huge deal. One case you might have seen is when you upload a profile picture to a website but other people don't see it instantly. After a few hours, everyone can see it. This is most likely because of eventual consistency.
Strong Consistency or Linearizability
Under this model, the system will provide the illusion of a single value. All users see the old value up to a certain point, after which they all start to observe the new value.
Here is an example:
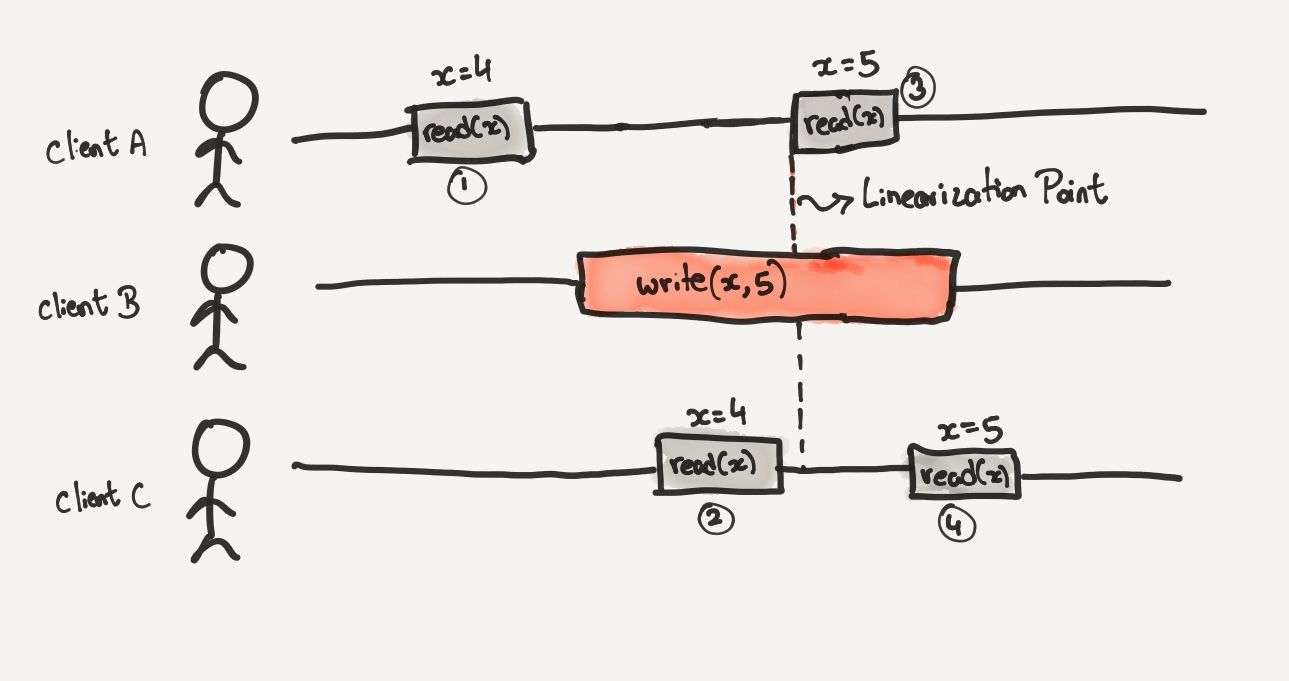
Client A, B, and C are all performing operations in parallel in the example.
The first read is from Client A. The value for x is 4.
Then Client B sets x to 5.
Client C reads the value of x, the database returns 4. x is still 4.
Then Client A makes a read request for x. This time it is the new value, 5. All subsequent read operations for x must return 5 to follow a strong consistency model.
Client C makes another read request for x. The value returned is 5, showcasing that the model is strongly consistent. If the last read returned the old value, 4, it would no longer be a strongly consistent model since it was not able to provide the illusion of a single data source.
The point at which the value of x flips from 4 to 5 is the linearization point. After the linearization point, all reads must return the newly written value.
A common way to ensure strong consistency is through consensus algorithms such as Raft (which I talked about last week), ZooKeeper Atomic Broadcast (ZAB), or Paxos.
Strong consistency models do not come for free, you will take performance hits. There are cases where you need strongly consistent data, Kubernetes is one such case. If you make a config update to increase the number of pods for your application, you want the scheduler to know about these changes as soon as possible. Another one is AWS S3, imagine uploading a file and having to wait a while just to see it on the cloud dashboard! That's an easy way to lose customers.
Consistency models exist to provide guarantees for our database systems and it's up to us to weigh the trade offs and choose the best one for the job. If reading stale data is not critical to your application, then eventual consistency will do the job. If you need the latest values as soon as possible, systems that implement strong consistency will do that for you at the cost of performance.
I cannot end this post without mentioning the resources used for this article:
- Designing Data Intensive Applications by Martin Kleppmann
- Database Internals by Alex Petrov
Thanks for reading. If you haven't already, please subscribe, it's free. Also, consider sharing it with a friend.